Claude Mythos Preview: Anthropic's Frontier Model Explained
Claude Mythos Preview is Anthropic's most powerful model. Benchmarks, Project Glasswing access, pricing at $25/$125, why it's not public.
Agentic Orchestration Kit for Claude Code.
Update (June 9, 2026): Mythos Preview has been superseded by the Mythos 5 generation. Anthropic shipped Claude Fable 5 and Claude Mythos 5, making a safeguarded Mythos-class model generally available for the first time. Fable 5 is on the public API and Claude Code at $10/$50 per million tokens; Mythos 5 (safeguards lifted) replaces Mythos Preview for Project Glasswing partners. This page remains as the record of the original April 2026 preview.
Claude Mythos Preview is Anthropic's first frontier-class model, sitting a full capability tier above Opus 4.7. Announced April 7, 2026, it was not generally available at launch. Access runs through Project Glasswing, an invitation-only partner program for 12 founding organizations and roughly 40 vetted critical-infrastructure operators. Pricing for partners is $25 per million input tokens and $125 per million output tokens, five times the cost of Opus 4.7. Anthropic has published a 244-page system card for the model, the first time the company has released system card documentation for an unreleased model.
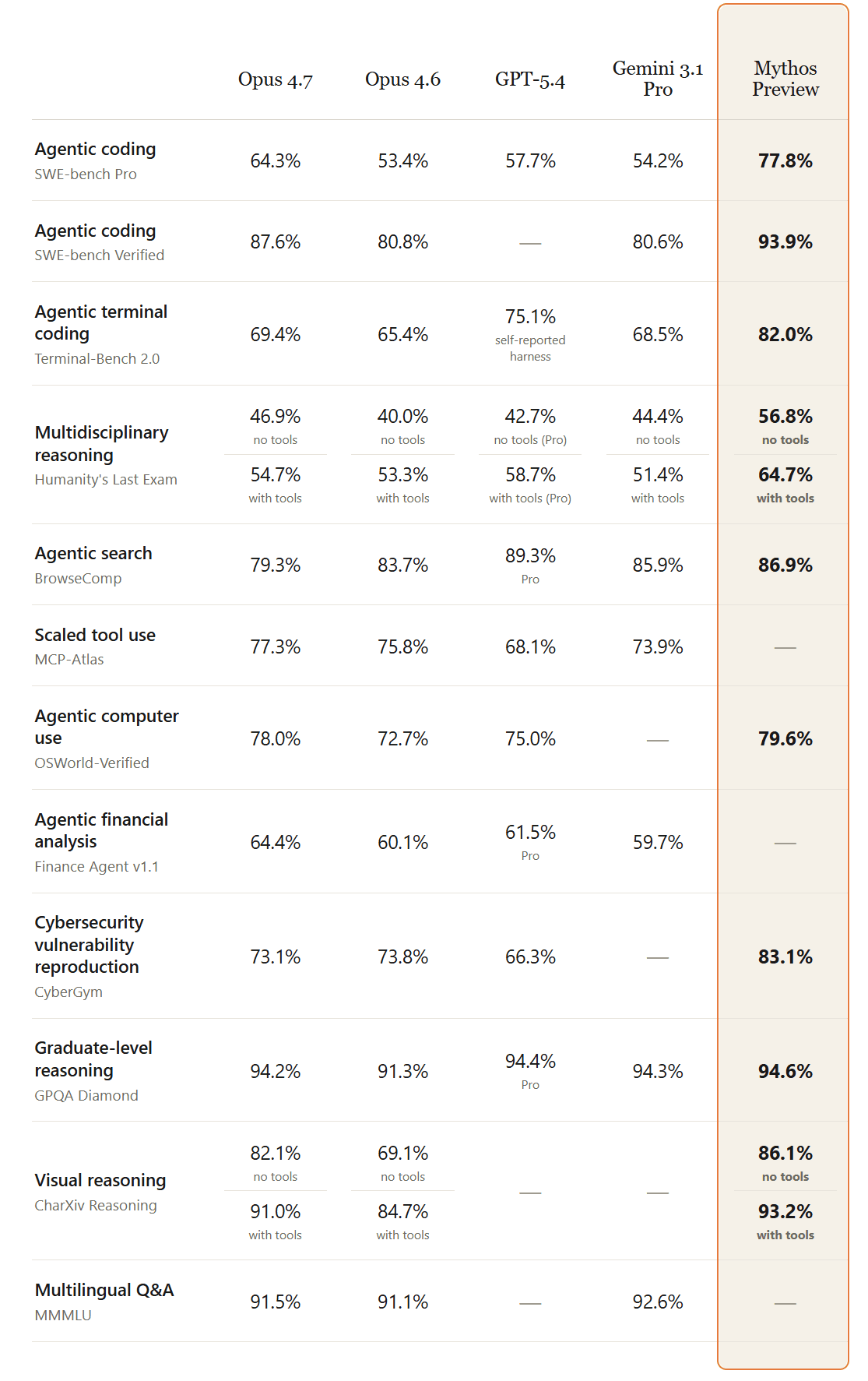
The numbers are genuinely unusual. Mythos Preview scores 93.9% on SWE-bench Verified, 77.8% on SWE-bench Pro, 82.0% on Terminal-Bench 2.0, and 97.6% on USAMO 2026. On cybersecurity it found thousands of zero-day vulnerabilities autonomously, including a 27-year-old OpenBSD TCP SACK remote code execution bug and a 17-year-old FreeBSD NFS RCE now tracked as CVE-2026-4747. Anthropic's own comparison chart shows the Firefox 147 JavaScript engine result is the clearest capability gap: Mythos produced 181 working exploits on the same harness where Opus 4.6 produced two. That is the short version of why this model is not on claude.ai today.
TL;DR: What You Need to Know About Claude Mythos
| Fact | Detail |
|---|---|
| What it is | Anthropic's frontier internal model, tier above Opus (internally "Capybara") |
| How to access | Project Glasswing partners only, no public API, no claude.ai, no Pro/Max plans |
| Announced | April 7, 2026 |
| Pricing | $25 input / $125 output per 1M tokens for partners |
| System card | 244 pages, published for an unreleased model |
| Why it is gated | Cyber-offense capability too advanced for current safeguard stack |
Key Specs: Claude Mythos Preview At a Glance
| Spec | Details |
|---|---|
| Announcement Date | April 7, 2026 |
| Internal Tier | "Capybara" (above Opus class) |
| API Identifier | Not disclosed publicly |
| Context Window | Not disclosed publicly |
| Availability | Project Glasswing partners only, gated research preview |
| Platforms (gated) | Claude API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry |
| Pricing | $25 input / $125 output per 1M tokens |
| System Card | ~244 pages (first for an unreleased Anthropic model) |
| Public Benchmarks | SWE-bench Verified 93.9%, SWE-bench Pro 77.8%, Terminal-Bench 2.0 82.0% |
| Cyber Result | Thousands of zero-days found autonomously, 100% on Cybench (35 CTFs) |
| Status | Preview, restricted, eventual broad release path not dated |
Anthropic has deliberately left several specs blank in public documentation. There is no published parameter count, no disclosed training compute, and no confirmed context window number. The company has said Mythos Preview "remains the best-aligned model we've trained" per its evaluation charts, while declining to place the model in a specific ASL tier in public-facing writeups.
The Capability Gap: Claude Mythos vs Opus 4.7
Anthropic's announcement of Claude Opus 4.7 describes that model as "less broadly capable than our most powerful model, Claude Mythos Preview." The benchmark deltas quantify what "less broadly capable" means in practice. Mythos leads Opus 4.7 on every head-to-head number Anthropic has published, with the gap running from a few points on graduate reasoning up to a generational leap on cybersecurity.
| Benchmark | Mythos Preview | Opus 4.7 | Gap |
|---|---|---|---|
| SWE-bench Verified | 93.9% | 87.6% | +6.3 points |
| SWE-bench Pro | 77.8% | 64.3% | +13.5 points |
| Terminal-Bench 2.0 | 82.0% | n/a | Mythos only |
| USAMO 2026 | 97.6% | n/a | Mythos only |
| Humanity's Last Exam (tools) | 64.7% | 54.7% | +10 points |
| GraphWalks BFS 256K-1M | 80.0% | n/a | Long-context reasoning lead |
| CyberGym | 83.1% | 73.1% | +10 points |
| Cybench (35 CTFs) | 100% | n/a | Full sweep |
The cybersecurity gap is the operational reason Mythos is not released. Anthropic states that Opus 4.7's training "experimented with efforts to differentially reduce these capabilities," which is polite wording for "we trained Opus 4.7 to be a worse hacker than Mythos on purpose." Opus 4.7 is the deliberately narrower slice of Mythos capability that Anthropic believes can ship with its current safeguard stack. If you already use Opus 4.7 for serious coding work, the mental model is that Mythos is the uncapped parent model.
One important caveat on all of the numbers above. Mythos benchmarks are run under Anthropic's own adaptive-thinking configuration at maximum effort, averaged across five trials. Competitor scores come from their own lab setups. This is not an apples-to-apples comparison in the way a single-operator benchmark harness would produce. For the cleaner head-to-head among publicly available models, see Opus 4.7 vs GPT-5.4 where both vendors have published numbers under comparable conditions.
Claude Mythos Benchmarks: Mythos vs the Field
The broader comparison puts Mythos Preview against every current frontier model. The shape of the result is consistent. Mythos leads everywhere, Opus 4.7 is the closest to it among generally available models, and GPT-5.4 and Gemini 3.1 Pro trail on agentic coding but stay close on graduate reasoning.
| Benchmark | Mythos | Opus 4.6 | Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| SWE-bench Verified | 93.9% | 80.8% | 87.6% | n/a | 80.6% |
| SWE-bench Pro | 77.8% | 53.4% | 64.3% | 57.7% | 54.2% |
| Terminal-Bench 2.0 | 82.0% | 65.4% | n/a | 75.1% | 68.5% |
| USAMO 2026 | 97.6% | 42.3% | n/a | 95.2% | 74.4% |
| GPQA Diamond | 94.6% | 91.3% | 94.2% | 94.4% | 94.3% |
| Humanity's Last Exam (tools) | 64.7% | 53.1% | 54.7% | 58.7% | 51.4% |
| OSWorld-Verified | 79.6% | 72.7% | 78.0% | 75.0% | n/a |
| GraphWalks BFS 256K-1M | 80.0% | 38.7% | n/a | 21.4% | n/a |
| CyberGym | 83.1% | 66.6% | 73.1% | n/a | n/a |
| Cybench (35 CTFs) | 100% | n/a | n/a | n/a | n/a |
Graduate reasoning on GPQA Diamond is effectively a four-way tie between Mythos, Opus 4.7, GPT-5.4, and Gemini 3.1 Pro, all sitting between 94.2% and 94.6%. Vellum's commentary on the Opus 4.7 launch called differences at this level "within noise." Where Mythos pulls away from the field is on the hardest agentic coding benchmarks (SWE-bench Pro, Terminal-Bench 2.0), on long-context reasoning (GraphWalks BFS), and on cybersecurity (CyberGym, Cybench). USAMO 2026 is the exception to the agentic coding story: Mythos and GPT-5.4 are close (97.6% vs 95.2%) because competition math rewards pure reasoning rather than multi-step tool use.
Read the benchmarks with discipline. Anthropic configured its own harness. Competitor numbers come from their own announcements, often under different tool budgets or different thinking modes. The gap is real, the shape is directionally correct, and the exact margins should not be treated as a final scoreboard. For production evaluation, benchmark on your own workload.
Cybersecurity: Where Claude Mythos Changed the Game
The cybersecurity section of Anthropic's Frontier Red Team post is where Mythos stops being a standard capability-bump story. The numbers are stark enough that independent practitioners have taken them seriously.
Three result clusters define the cyber story:
Zero-day discovery at scale. Mythos Preview found thousands of high or critical vulnerabilities autonomously across operating systems, browsers, and cryptography libraries. Over 99% of those findings were unpatched at the time Anthropic published. The vulnerabilities disclosed publicly include a 27-year-old OpenBSD TCP SACK remote crash bug (patched in OpenBSD 7.8), a 17-year-old FreeBSD NFS remote code execution hole now tracked as CVE-2026-4747, a 16-year-old FFmpeg H.264 heap write, and a guest-to-host virtual machine monitor memory corruption primitive.
Firefox and OSS-Fuzz as headline benchmarks. On a test harness targeting the Firefox 147 JavaScript engine (patched in 148), Opus 4.6 produced 2 working exploits. Mythos Preview produced 181. On Anthropic's internal OSS-Fuzz-style benchmark across roughly 1,000 repositories, Mythos produced 10 tier-5 full control-flow hijack exploits. Sonnet 4.6 and Opus 4.6 scored 0 at that tier. The exploits are not stack-smashing trivia. Several chained two or more memory corruption primitives across packet boundaries or between sandboxed components.

Defender-grade accuracy at low cost. On a sample of 198 manually reviewed vulnerability reports, Mythos matched human expert severity assessments exactly 89% of the time and within one severity level 98% of the time. The winning autonomous run for the OpenBSD SACK discovery cost under $50 in API compute. N-day exploit chains against the Linux kernel ran under $1,000 each.
Two independent voices matter here. The UK AISI evaluation confirmed Mythos is the first model to fully solve their "The Last Ones" 32-step corporate network attack simulation, succeeding in 3 of 10 attempts and averaging 22 of 32 steps where the next best model (Opus 4.6) averaged 16. AISI noted performance kept scaling with compute up to 100 million tokens without plateau. Simon Willison treated the results as a genuine inflection point rather than marketing, anchoring on independent practitioner signals: Greg Kroah-Hartman noted AI-generated kernel security reports went from "obviously wrong" to credible around a month before the announcement. Daniel Stenberg reported spending hours per day triaging the new wave.
Bruce Schneier is more skeptical of the framing. He accepts the capability jump as real but flags that Aisle Security replicated several Mythos-found bugs using older, cheaper public models, which he argues undercuts the exclusivity argument for gating Mythos specifically. His conclusion is that the capability is coming to broader models regardless, and the right response is to prepare for a world where "zero-day exploits are dime-a-dozen." The right frame for the capability is defensive: find and patch faster than attackers can find and weaponize. That is what Glasswing is structured to do.
Project Glasswing: How Claude Mythos Ships
Project Glasswing is the access channel for Mythos Preview. It is closed by design. Twelve founding partners got seats at launch:
- Amazon Web Services
- Anthropic
- Apple
- Broadcom
- Cisco
- CrowdStrike
- JPMorgan Chase
- Linux Foundation
- Microsoft
- NVIDIA
- Palo Alto Networks
Beyond the founders, Glasswing extended access to roughly 40 additional organizations "that build or maintain critical software infrastructure." Anthropic has not named those organizations publicly. The Claude for Open Source program is a separate track for maintainers of widely used open-source projects, with applications running through claude.com/contact-sales/claude-for-oss.
Anthropic committed $100 million in Mythos Preview usage credits across Glasswing partners and an additional $4 million in donations. The breakdown of the donation is $2.5 million to Alpha-Omega and the OpenSSF through the Linux Foundation, and $1.5 million to the Apache Software Foundation. The program also commits to a 90-day public report on vulnerabilities fixed through Glasswing-driven scanning work.
The structural argument for Glasswing is defender head-start. The organizations most likely to be targeted by advanced cyber-offense capability (cloud providers, operating system vendors, browser makers, critical software foundations, and major financial institutions) get access to a model with that capability first, for defensive use. They patch before that level of capability reaches the public model tier. When it does (and Anthropic has said this is a question of "when," not "if"), the highest-value targets have a shorter exposure window.
Reporters covering the announcement noted tensions in the structure. VentureBeat flagged that the Glasswing partner list skews heavily American and that smaller critical-infrastructure operators in other geographies have no clear path to access. Axios coverage reported active White House and Pentagon discussions about access for federal cybersecurity teams as of mid-April 2026, with no confirmed deployment. Expect the partner list to grow over the next two quarters.
Apply at anthropic.com/glasswing. Eligibility is concentrated on organizations that "build or maintain critical software infrastructure." If you are an individual developer, a small business, or a general enterprise, Glasswing is not an access path. The Claude for Open Source program is the likely channel for open-source maintainers.
Why Anthropic Is Not Releasing Claude Mythos Publicly
Anthropic's stated reasoning for gating Mythos Preview centers on three points. None of them are surprising, and each has pushback worth noting.
One. The cyber-offense capability is ahead of the current safeguard stack. Anthropic's Claude Opus 4.7 announcement says directly that releasing Mythos broadly "without new safeguards" would hand dangerous capability to attackers. The announcement explicitly calls Opus 4.7 "the first such model" trained with new cyber safeguards, with Mythos-class capabilities planned for eventual broad release after those safeguards prove out. Anthropic has not named a specific ASL tier for Mythos in public-facing documents, which is a notable gap given the Responsible Scaling Policy v3 framework.
Two. Opus 4.7 is the live test vehicle for Mythos-era safeguards. This is the most load-bearing part of the reasoning. Opus 4.7 ships with differential capability reduction on cyber tasks, automated detection of prohibited cybersecurity uses, and the new Cyber Verification Program for legitimate security professionals. Anthropic is explicit that learnings from real-world deployment of those safeguards will inform the eventual Mythos-class release. This is a novel approach in frontier model release: ship the weaker model first, observe how safeguards hold up, then ship the stronger one.
Three. The defender head-start argument. Partners who sit on critical infrastructure get Mythos first, patch what the model finds, and raise the floor of what public-tier capabilities can hit on launch day. The UK AISI evaluation endorses this framing with caveats, noting that current evaluation environments lack active defenders and may overstate what Mythos does against well-hardened systems.
The skeptical read is available and legitimate. Schneier notes that replication of Mythos-class capability by smaller open models (Aisle Security's work) suggests the exclusivity argument is time-limited. Zvi Mowshowitz's analysis treats the Glasswing approach as correct on substance but warns the coordination problem (getting every relevant defender patched before public parity) is genuinely hard. Both of those criticisms are compatible with Anthropic's position: gating Mythos buys time, it does not solve the underlying trajectory.
Access: Who Can Use Claude Mythos Preview
Claude Mythos access is concentrated on a small set of organizations. If you are not one of them, there is no path today.
Who can access Mythos:
- The 12 Project Glasswing founding partners
- Approximately 40 additional vetted critical-infrastructure organizations
- Applicants approved through Claude for Open Source (maintainers of widely used open-source projects)
- Government cybersecurity teams, pending discussions with Anthropic (no confirmed deployments as of April 16, 2026)
Who cannot access Mythos:
- Individual developers on claude.ai, Claude Pro, Max, Team, or Enterprise
- General enterprise customers on the Claude API, Amazon Bedrock, Google Cloud Vertex AI, or Microsoft Foundry
- Cursor, GitHub Copilot, Claude Code users, and every developer tool that defaults to Opus 4.7 today
- Any buyer at any price who is not approved through Glasswing or Claude for Open Source
For developer-grade work, Opus 4.7 is the correct and recommended stand-in. It sits one tier below Mythos on capability but is available through every standard Anthropic channel at $5/$25 per million tokens, a fifth of the Glasswing rate. If you want an operational comparison, see Opus 4.7 vs GPT-5.4 for the head-to-head against OpenAI's flagship, and our model selection guide for picking across the full Claude lineup.
Pricing and the Economic Model
Mythos Preview pricing for Glasswing partners is $25 per million input tokens and $125 per million output tokens. That is 5x the Opus 4.7 rate on both input and output.
The pricing signals two things. First, the $100 million in Glasswing usage credits Anthropic committed makes sense of the headline rate. At $125 per million output tokens, $100 million buys roughly 800 billion output tokens across partners. That is a meaningful compute subsidy, not a small perk. Second, the rate is not built for general developer workloads. It is built for security research organizations willing to pay a premium for compute budgets that support thousands of autonomous scanning runs.
No prompt caching or batch API pricing has been published for Mythos specifically. The model is available through Claude API, Amazon Bedrock research preview, Google Cloud Vertex AI private preview, and Microsoft Foundry, all gated behind Glasswing or individual approvals. Standard Claude API accounts cannot see the model identifier.
If the eventual broad release happens, most external commentary expects pricing to fall toward the Opus tier. Zvi Mowshowitz's speculative forecast suggests a Mythos-class model could reach general availability by September 2026. That is speculation, not an Anthropic commitment. Treat any date you see in the wild with appropriate skepticism.
What "Mythos-Class" Models Mean for the Future
The broader question is what the Mythos naming implies. Anthropic's internal model hierarchy places Mythos in a tier above Opus, referred to in leaks as "Capybara." Nothing in Anthropic's public writing confirms that Mythos will be the only model released at this tier. The phrase "Mythos-class models" appears in the Opus 4.7 announcement in the context of "a future broad release," which strongly suggests that Mythos Preview is the first of an internal class, not a one-off.
The operational implication for developers today is narrow. Opus 4.7 is the ceiling you can build on. The stricter instruction-following behavior, proactive self-verification, and the new xhigh effort level are downstream of training work that also produced Mythos. When Mythos-class capabilities eventually ship through general channels, the tooling changes should feel continuous rather than revolutionary. Anthropic has telegraphed this by framing Opus 4.7 as the test vehicle for Mythos-era safeguards.
Two things to watch over the next two quarters. First, Anthropic's 90-day Glasswing report, due around early July 2026, should name specific vulnerabilities patched through the program. That report is the first real quantification of whether the defender head-start argument works in practice. Second, any change in the RSP tier designation for Mythos would signal Anthropic's thinking on eventual broad release. A formal ASL-4 or ASL-5 classification would slow any timeline. No change would keep the September 2026 speculative timeline plausible.
For a wider view of how Mythos fits into Anthropic's release history, see the complete Claude model timeline from Claude 3 through today. Mythos Preview is the first model in that timeline that shipped with a published system card before reaching general availability.
Frequently Asked Questions
Is Claude Mythos available to the public?
No. Claude Mythos Preview is available only through Project Glasswing, which is limited to 12 founding partners and approximately 40 additional vetted critical-infrastructure organizations. There is no public API, no claude.ai access, and no Pro, Max, Team, or Enterprise plan that includes Mythos. Individual developers, small businesses, and general enterprise buyers cannot access Mythos at any price today.
How do I access Claude Mythos?
Apply through anthropic.com/glasswing if your organization builds or maintains critical software infrastructure. Open-source project maintainers can apply through the Claude for Open Source program at claude.com/contact-sales/claude-for-oss. For developer-grade work, Opus 4.7 is the recommended and accessible alternative at $5/$25 per million tokens through all standard Claude API channels.
When will Claude Mythos be released?
Anthropic has not committed to a broad release date. The Opus 4.7 announcement describes Opus 4.7 as the test vehicle for cyber safeguards that will eventually support "a broad release of Mythos-class models." Independent analysts like Zvi Mowshowitz have speculated on a late-2026 timeframe, but no such date is confirmed by Anthropic. Expect the 90-day Glasswing report due around early July 2026 to clarify the trajectory.
Claude Mythos vs Opus 4.7: which is more powerful?
Mythos Preview leads Opus 4.7 on every head-to-head benchmark Anthropic has published. Gaps range from +6.3 points on SWE-bench Verified to +13.5 points on SWE-bench Pro, with a generational lead on cybersecurity benchmarks. Opus 4.7 was trained with deliberate differential reduction of cyber capabilities as a safety measure. If you need Opus-tier agentic coding today and cannot access Glasswing, Opus 4.7 is the correct choice. If you need Mythos-tier capability, you need Glasswing approval.
Is Claude Mythos more powerful than GPT-5.4?
Yes, on the benchmarks where Anthropic and OpenAI have published comparable numbers. Mythos leads SWE-bench Pro by 20.1 points (77.8% to 57.7%), USAMO 2026 by 2.4 points (97.6% to 95.2%), and Humanity's Last Exam with tools by 6 points (64.7% to 58.7%). GPT-5.4 is a strong frontier model, but Mythos is explicitly one tier higher in Anthropic's lineup. Note that benchmark configurations differ across vendors.
What is Project Glasswing?
Project Glasswing is Anthropic's defensive cybersecurity program and the only access channel for Claude Mythos Preview. It includes 12 founding partners (AWS, Anthropic, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, Linux Foundation, Microsoft, NVIDIA, Palo Alto Networks), approximately 40 additional critical-infrastructure organizations, $100 million in usage credits, and $4 million in donations ($2.5M to Alpha-Omega and OpenSSF, $1.5M to Apache Software Foundation). Learn more at anthropic.com/glasswing.
Claude Mythos pricing: how much does it cost?
For Glasswing partners, Mythos Preview is $25 per million input tokens and $125 per million output tokens. That is 5x the Opus 4.7 rate of $5/$25. The $100M in Glasswing credits offsets this headline rate for approved partners. Prompt caching and batch API discounts have not been published for Mythos specifically. General customers cannot purchase Mythos at any price.
Is Claude Mythos available on Amazon Bedrock?
Mythos is available as a gated research preview on Amazon Bedrock, a private preview on Google Cloud Vertex AI, and through Microsoft Foundry, all restricted to Glasswing partners. Standard Bedrock, Vertex AI, and Foundry accounts cannot see the model identifier. If you need Claude capability on Bedrock, Opus 4.7 is available through standard Bedrock accounts at $5/$25 per million tokens.
Is Claude Mythos safe?
Anthropic's evaluation describes Mythos Preview as "the best-aligned model we've trained," with the lowest rates of misaligned behavior across their evaluation suite. The published 244-page system card documents safety testing. The safety concern that justifies gating is not misalignment but rather the raw offensive cyber capability, which Anthropic believes is ahead of the current safeguard stack. The UK AISI independent evaluation agreed Mythos represents "a step up" in cyber capabilities but noted current evaluation environments lack active defenders and may overstate real-world attacker advantage.
What is a Mythos-class model?
"Mythos-class" is Anthropic's phrasing for the capability tier above Opus, referenced internally as "Capybara." The Opus 4.7 announcement uses the term in the context of "a future broad release of Mythos-class models," suggesting Mythos Preview is the first in an internal class rather than a one-off. Future Mythos-class models would presumably ship to the public once safeguard infrastructure catches up with their capability. Opus 4.7 is the live test vehicle for those safeguards.
Last updated on