Claude Opus 4.7: Vision, Verification, and a New Effort Tier
Opus 4.7 adds 3x vision resolution, xhigh effort, stricter instruction-following, and 70% CursorBench. Same $5/$25 pricing.
Agentic Orchestration Kit for Claude Code.
Anthropic has since released Claude Opus 4.8. This page documents 4.7 for historical reference.
Claude Opus 4.7 is Anthropic's latest flagship model, released April 16, 2026. It hits 64.3% on SWE-bench Pro, beating GPT-5.4 (57.7%) and Gemini 3.1 Pro (54.2%) on what is currently the toughest agentic coding benchmark. It verifies its own outputs before reporting, processes images at more than three times the resolution of any previous Claude, and introduces a new xhigh effort level that sits between high and max. Instruction-following is stricter, vision capabilities took a generational leap, and pricing stays at $5/$25 per million tokens.
The model ships alongside a Cyber Verification Program for security professionals, higher-resolution image support across the API, and task budgets in public beta for managing token spend on long-running agentic sessions. It is Anthropic's most capable generally available model. The frontier-class tier above it, Claude Mythos Preview, is released only through Project Glasswing to 12 founding partners and a limited set of critical-infrastructure organizations.
Key Specs
| Spec | Details |
|---|---|
| API ID | claude-opus-4-7 |
| Release Date | April 16, 2026 |
| Context Window | 1M tokens (GA) |
| Max Output | 128,000 tokens |
| Max Image Input | 2,576px long edge (3.75 MP) |
| Effort Levels | low, medium, high, xhigh, max (xhigh is new) |
| Thinking | Adaptive only (thinking.budget_tokens removed) |
| Task Budgets | Public beta (task-budgets-2026-03-13 header) |
| Tokenizer | New generation (~1.0-1.35x more tokens than 4.6) |
| Pricing | $5 input / $25 output per 1M tokens |
| Availability | Claude API, Bedrock, Vertex AI, Foundry, GitHub Copilot, Snowflake Cortex |
| Status | Superseded by Opus 4.8 |
What Changed: The Practical Improvements
Anthropic's internal teams use Claude Code daily, and each model release reflects what they learned from the previous one. Opus 4.7's changes are specific:
Self-verification before reporting. The model checks its own work before presenting results. It catches logical faults during planning and validates outputs against the original requirements. Intuit describes it as "catching its own logical faults during the planning phase and accelerating execution." Vercel's team observed it doing "proofs on systems code before starting work, which is new behavior."
3x vision resolution. Opus 4.7 accepts images up to 2,576 pixels on the long edge (roughly 3.75 megapixels), more than three times what prior Claude models supported. No API parameter changes needed. On XBOW's visual-acuity benchmark, it scored 98.5% compared to 54.5% for Opus 4.6. It reads chemical structures, complex technical diagrams, and dense charts that previous models struggled with.
Stricter instruction-following. The model interprets instructions more literally than Opus 4.6. This is a double-edged upgrade: prompts that relied on the model filling in implied context may need adjustment. The flip side is that explicit instructions produce more predictable results. Notion found it was the first model to pass their implicit-need tests.
New xhigh effort level. The effort scale now has five levels: low, medium (implied between low and high), high, xhigh, and max. Claude Code defaults to xhigh for all plans. The xhigh level gives deeper reasoning than high without the full cost of max. Hex's CTO noted that "low-effort Opus 4.7 is roughly equivalent to medium-effort Opus 4.6."
Longer autonomous sessions. Cognition (Devin) reports the model "works coherently for hours, pushes through hard problems." Factory saw 10-15% higher task success rates with fewer instances of the model stopping halfway through complex work.
Updated tokenizer. The same input may map to roughly 1.0-1.35x more tokens depending on content type. Combined with deeper thinking at higher effort levels, token usage increases. Controls include the effort parameter, task budgets, and conciseness prompting. Check the migration guide for details.
Adaptive Thinking and the Effort Dial
Adaptive thinking is the only thinking-on mode in Opus 4.7. Extended-thinking budgets are gone. You set thinking: {type: "adaptive"} and the model decides how long to reason based on task complexity. Adaptive thinking is off by default on Opus 4.7. Requests without the thinking field run without thinking at all.
You control depth through the effort parameter, which now has five levels:
| Level | When to use |
|---|---|
| low | Classification, extraction, formatting. Thinking off works too. |
| medium | General queries, short summaries, docs lookups. |
| high | Most intelligence-sensitive work. Good default for API callers. |
| xhigh | Coding, multi-step reasoning, agentic work. Claude Code default. |
| max | Correctness-critical evals where cost is not the primary concern. |
Thinking content is also omitted from responses by default. If your product streams reasoning to users, set thinking.display: "summarized" to restore visible progress. This is a silent change, no error is raised, so check any surface that used to show a reasoning trace.
Where Mythos Fits
Opus 4.7 is Anthropic's most capable generally available model. It is not Anthropic's most capable model overall. That distinction belongs to Claude Mythos Preview, announced April 7, 2026 and described by Anthropic as "the best-aligned model we've trained." Mythos is released through Project Glasswing to 12 founding partners (AWS, Apple, Cisco, CrowdStrike, Google, JPMorgan Chase, Microsoft, NVIDIA, Palo Alto Networks, Broadcom, Linux Foundation, and Anthropic) plus roughly 40 vetted critical-infrastructure organizations. Pricing for Glasswing partners: $25/$125 per million input/output tokens.
Mythos Preview scores 77.8% on SWE-bench Pro, 82.0% on Terminal-Bench 2.0, and found thousands of zero-day vulnerabilities autonomously including a 27-year-old OpenBSD TCP/SACK RCE. Opus 4.7 is the deliberately narrower slice of that capability surface, particularly in cybersecurity where Anthropic applied differential capability reduction during training. Anthropic's stated plan is that Opus 4.7 serves as the test vehicle for cyber safeguards before eventual broad release of Mythos-class models to the general public. For the full picture see our Claude Mythos guide.
Benchmark Results
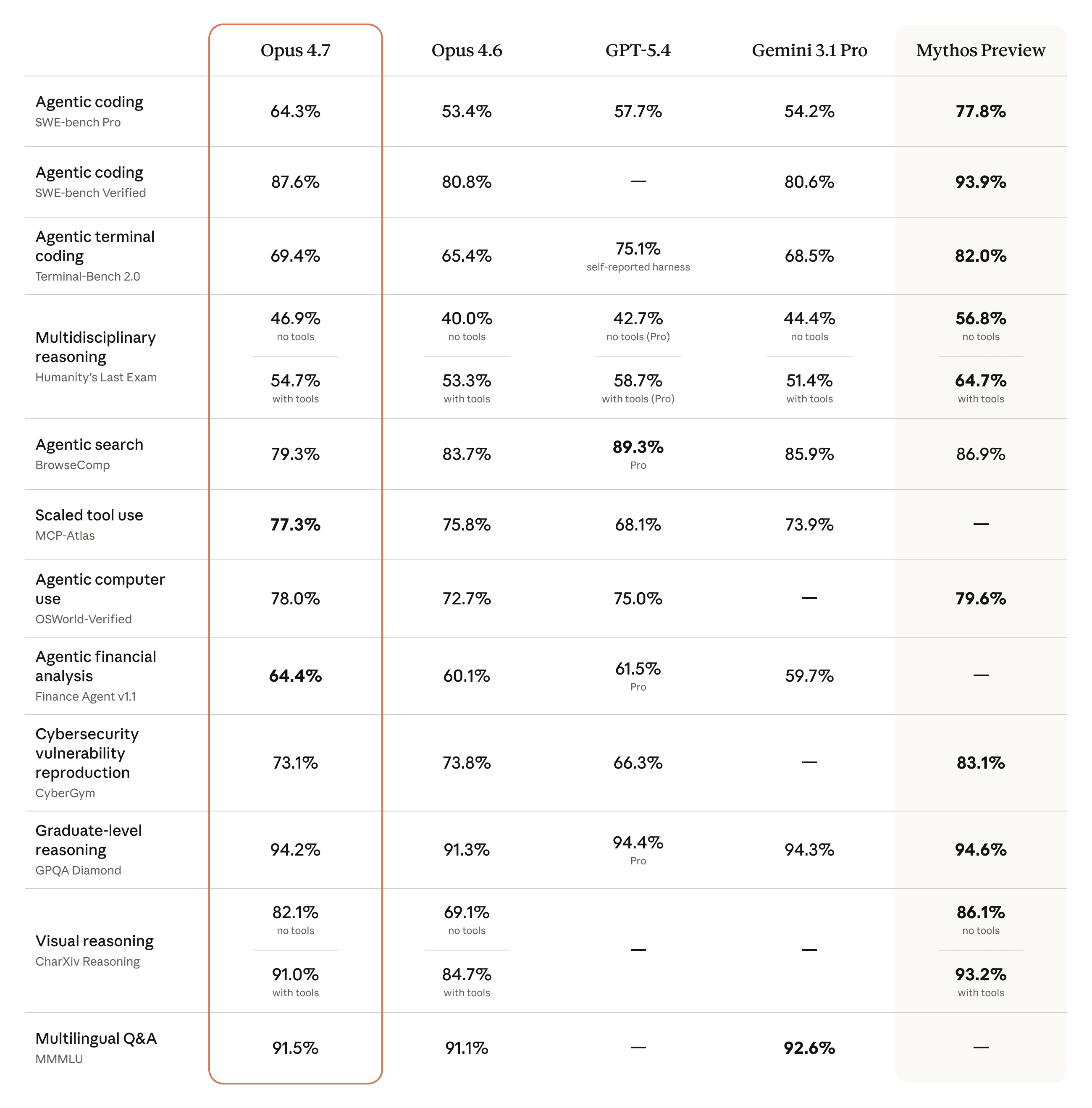
Opus 4.7 posted gains across coding, vision, legal, finance, and agentic evaluations:
| Benchmark | Opus 4.7 | Opus 4.6 | Notable |
|---|---|---|---|
| SWE-bench Pro | 64.3% | 53.4% | Beats GPT-5.4 (57.7%) and Gemini 3.1 Pro (54.2%) |
| CursorBench | 70% | 58% | +12 points |
| Terminal-Bench 2.0 | 3 new tasks solved | baseline | Tasks no prior model could pass |
| XBOW Visual Acuity | 98.5% | 54.5% | +44 points, generational leap |
| BigLaw Bench | 90.9% | -- | Harvey, high effort |
| GDPval-AA | SoTA | SoTA | Maintained frontier position |
| General Finance | 0.813 | 0.767 | AlphaSense research-agent module |
| OfficeQA Pro | 21% fewer errors | baseline | Databricks evaluation |
| Notion Agent | +14% resolution | baseline | 1/3 the tool errors of 4.6, fewer tokens |
CursorBench measures real-world coding assistance quality, the benchmark most directly relevant to developers using Claude in their editor. The jump from 58% to 70% represents meaningfully better code suggestions, completions, and refactors.
The XBOW visual-acuity result deserves attention. Going from 54.5% to 98.5% is not incremental improvement. This is the first Claude model where you can reliably pass in high-resolution screenshots, architectural diagrams, or scientific figures and expect accurate interpretation.
On Terminal-Bench 2.0, Opus 4.7 solved three tasks that no previous Claude model (or competing frontier model) could handle, including fixing a race condition that required multi-file reasoning across a complex codebase.
Rakuten reported 3x more production tasks resolved compared to Opus 4.6, with double-digit gains in Code Quality and Test Quality scores. CodeRabbit saw recall improve over 10%, noting the model is "a bit faster than GPT-5.4 xhigh."
Vision: A Generational Leap
Previous Claude models were limited to lower-resolution image inputs. Opus 4.7 raises the ceiling to 2,576 pixels on the long edge, roughly 3.75 megapixels. This is a model-level change with no API parameters to toggle.
What this means in practice:
- Code screenshots at full resolution, no more squinting artifacts
- Technical diagrams with fine labels and small text rendered accurately
- Chemical structures and scientific notation parsed correctly (Solve Intelligence confirmed this)
- Charts and graphs with dense data points interpreted without hallucinating values
Higher-resolution images consume more tokens. If you are passing images where fine detail is not critical, downsample before sending to manage costs.
Cybersecurity and the Cyber Verification Program
Opus 4.7 includes automated safeguards that detect and block requests indicating prohibited or high-risk cybersecurity uses. These safeguards are part of Anthropic's broader Project Glasswing initiative and serve as a testing ground for eventual broader release of their more capable Mythos-class models.
Legitimate security professionals can access cybersecurity capabilities through Anthropic's new Cyber Verification Program. This covers vulnerability research, penetration testing, and red-teaming. Apply at claude.com/form/cyber-use-case.
The cyber capabilities in Opus 4.7 are intentionally less advanced than what Anthropic's internal Mythos Preview can do. Training included differential reduction of certain cyber capabilities as a safety measure.
Safety Profile
Opus 4.7 maintains a similar safety profile to Opus 4.6 with targeted improvements in honesty and resistance to prompt injection attacks. Anthropic's assessment describes it as "largely well-aligned and trustworthy, though not fully ideal."
One noted weakness: the model can be overly detailed in harm-reduction advice on controlled substances. The full details are in the Claude Opus 4.7 System Card (PDF).
New API and Product Features
Alongside the model, Anthropic shipped:
Task budgets (public beta). Guide Claude's token spend across longer agentic runs. Set a budget and the model plans its token usage accordingly rather than spending freely.
Higher-resolution image support. The 2,576-pixel limit applies across the API for all Opus 4.7 requests. No opt-in needed.
/ultrareview in Claude Code. A dedicated slash command that runs a focused review session, flagging bugs and design issues. Pro and Max users get 3 free ultrareviews.
Auto mode for Max users. Claude makes decisions autonomously with fewer interruptions and managed risk. Previously limited to Enterprise plans.
Pricing: $5/$25 With a Tokenizer Asterisk
No price increase. Unchanged from Opus 4.6:
| Tier | Cost |
|---|---|
| All contexts | $5 input / $25 output per 1M tokens |
| Prompt caching | Up to 90% savings |
| Batch processing | 50% savings |
| US-only inference | 1.1x standard pricing |
The list price is unchanged. The tokenizer is not. Opus 4.7 uses a new tokenizer that can encode the same input into 1.0 to 1.35x as many tokens (up to roughly 35% more), so the effective cost per request may rise even while the per-token rate holds. For token-sensitive workloads, benchmark your specific content before migrating.
Is Claude Opus 4.7 Free?
Opus 4.7 is included at no extra cost on Claude Pro, Max, Team, and Enterprise plans. The free tier on claude.ai does not include Opus 4.7. For API access, the $5/$25 per million token pricing applies. GitHub Copilot users get Opus 4.7 with a 7.5x premium request multiplier as promotional pricing through April 30, 2026.
Claude Opus 4.7 API Pricing
$5 per million input tokens. $25 per million output tokens. Pricing is identical across Anthropic's API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry, and Snowflake Cortex. US-only inference carries a 1.1x multiplier. Prompt caching cuts cached-read cost by 90%. The Batch API adds a further 50% discount for non-urgent jobs. There is no long-context premium on the 1M window.
How to Use Opus 4.7 in Claude Code
Switch your default model:
For per-session overrides:
The model is available across claude.ai, the Messages API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry, Snowflake Cortex, and GitHub Copilot (Pro+, Business, Enterprise, with a 7.5x premium request multiplier as promo pricing through April 30, 2026). The API model identifier is claude-opus-4-7.
To use the new xhigh effort level:
Opus 4.7 vs Opus 4.6: What Changed
| Feature | Opus 4.6 | Opus 4.7 |
|---|---|---|
| SWE-bench Pro | 53.4% | 64.3% (+10.9 points) |
| CursorBench | 58% | 70% (+12 points) |
| Terminal-Bench 2.0 | baseline | +3 tasks prior models could not solve |
| XBOW Visual Acuity | 54.5% | 98.5% (+44 points) |
| Notion Agent resolution | baseline | +14% with 1/3 the tool errors |
| Finance Agent (AlphaSense) | 0.767 | 0.813 |
| OfficeQA Pro (Databricks) | baseline | 21% fewer errors |
| Max image input | 1,568px (1.15 MP) | 2,576px long edge (3.75 MP, >3x more) |
| Effort levels | low, high, max | low, medium, high, xhigh, max |
| Default effort | high | xhigh (Claude Code) |
| Thinking | Extended with budget_tokens | Adaptive only (budget_tokens returns 400) |
| Sampling params | temperature/top_p/top_k work | Set any non-default value: 400 error |
| Thinking output default | Visible | Omitted (opt in with display: summarized) |
| Self-verification | Basic | Proactive output verification |
| Instruction-following | Standard | Stricter, more literal |
| Tokenizer | Previous generation | Updated (1.0-1.35x more tokens) |
| Cyber safeguards | Not present | Real-time detection and blocking |
| Task budgets | Not available | Public beta (task-budgets-2026-03-13) |
| Pricing | $5/$25 per 1M | $5/$25 per 1M (unchanged) |
The core story is vision, verification, and a new economic model for thinking. The 3x resolution jump makes Opus 4.7 the first Claude model where image understanding is genuinely reliable for professional use. The self-verification behavior means fewer rounds of "wait, let me check that" from the user. Adaptive thinking replaces the old budget-based thinking system, and the tokenizer update means benchmarking token usage is a worthwhile pre-migration step.
For model selection, the upgrade path is straightforward. If you use Opus for complex work, switch to 4.7. Review prompts that depended on loose instruction interpretation, strip temperature/top_p/top_k from API calls, and if you show thinking traces to users set display: "summarized". For the detailed migration playbook see the Opus 4.7 best practices guide. If you want the head-to-head numbers against OpenAI's flagship, see Opus 4.7 vs GPT-5.4.
Frequently Asked Questions
Is Claude Opus 4.7 free? Opus 4.7 is included on Claude Pro, Max, Team, and Enterprise plans. It is not on the claude.ai free tier. API access is paid at $5/$25 per million tokens.
What is the Opus 4.7 context window? 1 million tokens, generally available at standard pricing. Max output is 128,000 tokens per response.
What is the new xhigh effort level? A fifth tier between high and max. Claude Code defaults to xhigh for all plans. It gives deeper reasoning than high without the full cost of max.
Does Opus 4.7 use a new tokenizer? Yes. The same input may encode into 1.0 to 1.35x as many tokens as on Opus 4.6. List pricing is unchanged, but effective cost per request can rise on token-heavy content.
How does Opus 4.7 compare to Mythos? Mythos Preview is Anthropic's most capable internal model and has not been publicly released. Opus 4.7 is the most capable generally available model. Anthropic's stated goal is eventual broad release of Mythos-class models.
What API changes break existing 4.6 code? Three things. thinking.budget_tokens returns 400. Setting temperature, top_p, or top_k to any non-default value returns 400. thinking.display defaults to "omitted", silently hiding reasoning traces unless you opt in.
Last updated on