Claude Opus 4.8 Pricing, Benchmarks, and Is It Free
Claude Opus 4.8 API pricing ($5/$25 per 1M tokens), benchmarks, specs, and whether it is free. Grounded in Anthropic's official release.
Agentic Orchestration Kit for Claude Code.
Claude Opus 4.8 costs $5 per million input tokens and $25 per million output tokens on the standard API tier, or $10/$50 per million in Fast mode. It is not free on the claude.ai free tier, but it is included at no extra cost on Pro, Max, Team, and Enterprise. It scores 84% on Online-Mind2Web for browser agent work and is the only model to complete every case end-to-end on Hebbia's Super-Agent benchmark. The model API ID is claude-opus-4-8, and it shipped May 28, 2026. Every number on this page is grounded in Anthropic's official Opus 4.8 announcement and system card.
Update (June 9, 2026): Opus 4.8 is no longer Anthropic's most capable generally available model. Claude Fable 5, the first public Mythos-class model, now sits above it. Opus 4.8 keeps a central role: it is the fallback model that handles any Fable 5 request the safeguard classifiers flag (cybersecurity, biology, chemistry, or distillation), which happens in under 5% of sessions. It remains the reliable default for daily agentic coding.
Claude Opus 4.8 is Anthropic's flagship Opus model. Beyond the pricing and browser-agent numbers above, it takes the highest recorded score on Sierra's Legal Agent Benchmark as the first model to break 10% on the all-pass standard, and Anthropic reports it is roughly four times less likely than Opus 4.7 to let flaws in its own code pass unremarked. Fast mode runs at 2.5x the speed of the standard tier and is three times cheaper than Fast mode on previous Opus models.
The model ships alongside Dynamic Workflows in Claude Code, a new Effort Control surface in claude.ai and Cowork, and a Messages API change that lets developers inject system entries mid-task. It was Anthropic's most capable generally available model until Claude Fable 5 shipped on June 9, 2026. The Mythos-class tier that once sat gated above it (first Mythos Preview, now Mythos 5) is finally public in safeguarded form as Fable 5, with Opus 4.8 serving as the fallback when Fable 5's classifiers flag a request.
Quick Answers: Pricing, Free Access, and Specs
If you came here for one number, here it is. These are the facts most people search for, answered directly and grounded in Anthropic's release.
- How much does Opus 4.8 cost? $5 per million input tokens and $25 per million output tokens on the standard API tier. Fast mode is $10 input / $50 output per million.
- Is Claude Opus 4.8 free? Not on the claude.ai free tier. It is included at no extra usage cost on Pro, Max, Team, and Enterprise. API access is paid at the rates above.
- How many parameters does Opus 4.8 have? Anthropic does not publish a parameter count for Opus 4.8 (or any Claude model). Anyone quoting a specific number is guessing. What Anthropic does disclose is the context window, output limit, and pricing, all listed below.
- What is the context window? 1 million tokens, generally available at standard pricing, with a 128,000-token max output.
- When was it released? May 28, 2026. The API ID is
claude-opus-4-8. - How does it compare to GPT-5.5? Opus 4.8 matches GPT-5.5 at parity on cost on Hebbia's Super-Agent benchmark and leads on Online-Mind2Web; GPT-5.5 with the Codex CLI harness still leads Terminal-Bench 2.1 at 83.4%. Full table below.
For the cheaper, higher-throughput option, see how Fast mode pricing works below. For the model that now sits above Opus 4.8, see Fable 5 and Mythos 5.
Key Specs
| Spec | Details |
|---|---|
| API ID | claude-opus-4-8 |
| Release Date | May 28, 2026 |
| Context Window | 1M tokens (GA) |
| Max Output | 128,000 tokens (up to 300,000 via Batch API extended-output beta) |
| Knowledge Cutoff | January 2026 (reliable and training data cutoff) |
| Max Image Input | 2,576px long edge (3.75 MP, carried forward from Opus 4.7) |
| Effort Levels | high (default), xhigh, max (with Fast mode toggle) |
| Thinking | Adaptive only |
| Tokenizer | Carried forward from Opus 4.7 generation |
| Pricing | $5 input / $25 output per 1M tokens (standard); $10 / $50 per 1M (Fast mode) |
| Availability | Claude API, claude.ai, Cowork, Claude Code (Enterprise, Team, Max for Dynamic Workflows) |
| Status | Active, current recommended Opus |
What Changed: The Practical Improvements
Anthropic frames Opus 4.8 as a quality and reliability release rather than a numbers-on-the-board release. The official summary is direct: "It builds on Opus 4.7 with improvements across benchmarks, and is a more effective collaborator."
Honesty and self-checking, quantified. Opus 4.7 introduced proactive output verification. Opus 4.8 tightens that further. Anthropic reports the new model is "around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked." Tom Pritchard, a Staff Engineer working with the model, described the experience: "Claude Opus 4.8 has noticeably better judgment. In Claude Code, it asks the right questions, catches its own mistakes, pushes back when a plan isn't sound, and builds up confidence around complex, multi-service explorations before making big changes."
Step efficiency on tool calling. Cursor's Michael Truell, Co-Founder and CEO, reported: "On CursorBench, Claude Opus 4.8 exceeds prior Opus models across every effort level. Tool calling is meaningfully more efficient, using fewer steps for the same intelligence, and it carries end-to-end tasks through." The pattern partners describe is the same intelligence ceiling using less context and fewer tool round-trips, which matters more for agentic workloads than for one-shot coding.
Longer autonomous sessions, end-to-end. Anthropic's Dynamic Workflows announcement notes that "with Opus 4.8, the agents can run for even longer." On Hebbia's internal evaluation, Kay Zhu (Co-Founder and CTO) reported Opus 4.8 was "the only model to complete every case end-to-end" on their Super-Agent benchmark, "beating prior Opus models and GPT-5.5 at parity on cost." Scott Wu, Cognition's CEO, said the model "uses tools cleanly and follows instructions with the consistency our autonomous engineering workloads need to keep running unattended. It improves on Opus 4.6 and fixes the comment-verbosity and tool-calling issues we saw with Opus 4.7."
Browser and computer use jumped. Miguel Gonzalez, a Tech Lead working on browser agents, reported: "Claude Opus 4.8 is the strongest computer-use and browser-agent model we've tested, scoring 84% on Online-Mind2Web, which is a meaningful jump over both Opus 4.7 and GPT-5.5." That moves browser agents out of the "sometimes works" category for real workloads.
Multimodal cost efficiency. Databricks' Hanlin Tang, CTO of Neural Networks, said the model "reasons directly over PDFs, diagrams, and other unstructured content at 61% cheaper token cost than Opus 4.7." The 3x vision resolution from Opus 4.7 carries forward; Opus 4.8 spends fewer tokens to get the same result on document understanding.
Style and voice control over long sessions. Katie Parrott, a Staff Writer, described Opus 4.8 as "a major quality-of-life update over Opus 4.7: faster, easier to collaborate with, and better at carrying context and style direction across a long session." That maps to the kind of long-context use editorial and research teams put on flagship models.
The Effort Dial, Now in claude.ai
Opus 4.8 carries forward the same effort scale as Opus 4.7 and adds one new setting in Claude Code: ultracode. One default worth flagging: Opus 4.8 defaults to high effort in Claude Code, where Opus 4.7 defaulted to xhigh. claude.ai now exposes an effort selector to all users via the new Effort Control surface, and Cowork picks up the same control.
| Level | When to use |
|---|---|
| high | Balances tokens and intelligence. Default on Opus 4.8 in Claude Code and in the Messages API. |
| xhigh | Deeper reasoning for coding, multi-step, and agentic work at higher token spend. Default on Opus 4.7. |
| ultracode | A Claude Code setting (not an API effort level): sends xhigh plus auto-triggered Dynamic Workflows. Session-only. New in 4.8. |
| max | Correctness-critical evals and the deepest agentic plans. |
The user-facing logic in claude.ai is unchanged from how API callers already think about it: "On higher effort settings, Claude will think more frequently and more deeply to give better responses. On lower effort settings, Claude will respond faster and use up a user's rate limits more slowly." ultracode is the new tier introduced with 4.8 and is the lowest-friction way to let Claude decide when a task warrants a Dynamic Workflow without the explicit "create a workflow" trigger phrase. For background on the original five-level scheme and the introduction of xhigh, see the Opus 4.7 release notes.
Where Mythos Fits
At launch, Opus 4.8 was Anthropic's most capable generally available model, though never its most capable model overall. As of June 9, 2026, Claude Fable 5 holds the generally-available top spot, and the Mythos Preview that once sat gated above the Opus line has been succeeded by Mythos 5. The section below reflects the picture at Opus 4.8's launch.
What changes with Opus 4.8 is how close the alignment profile sits to Mythos. Anthropic's assessment states Opus 4.8 "reaches new highs on our measures of prosocial traits like supporting user autonomy and acting in the user's best interest" and "rates of misaligned behavior (such as deception or cooperation with misuse) that are substantially lower than Opus 4.7, and similar to our best-aligned model, Claude Mythos Preview." Anthropic also signals timing: "Models of this capability level require stronger cyber safeguards before they can be generally released. We're making swift progress on developing these safeguards and expect to be able to bring Mythos-class models to all our customers in the coming weeks." For the full picture, see our Claude Mythos guide.
Benchmark Results
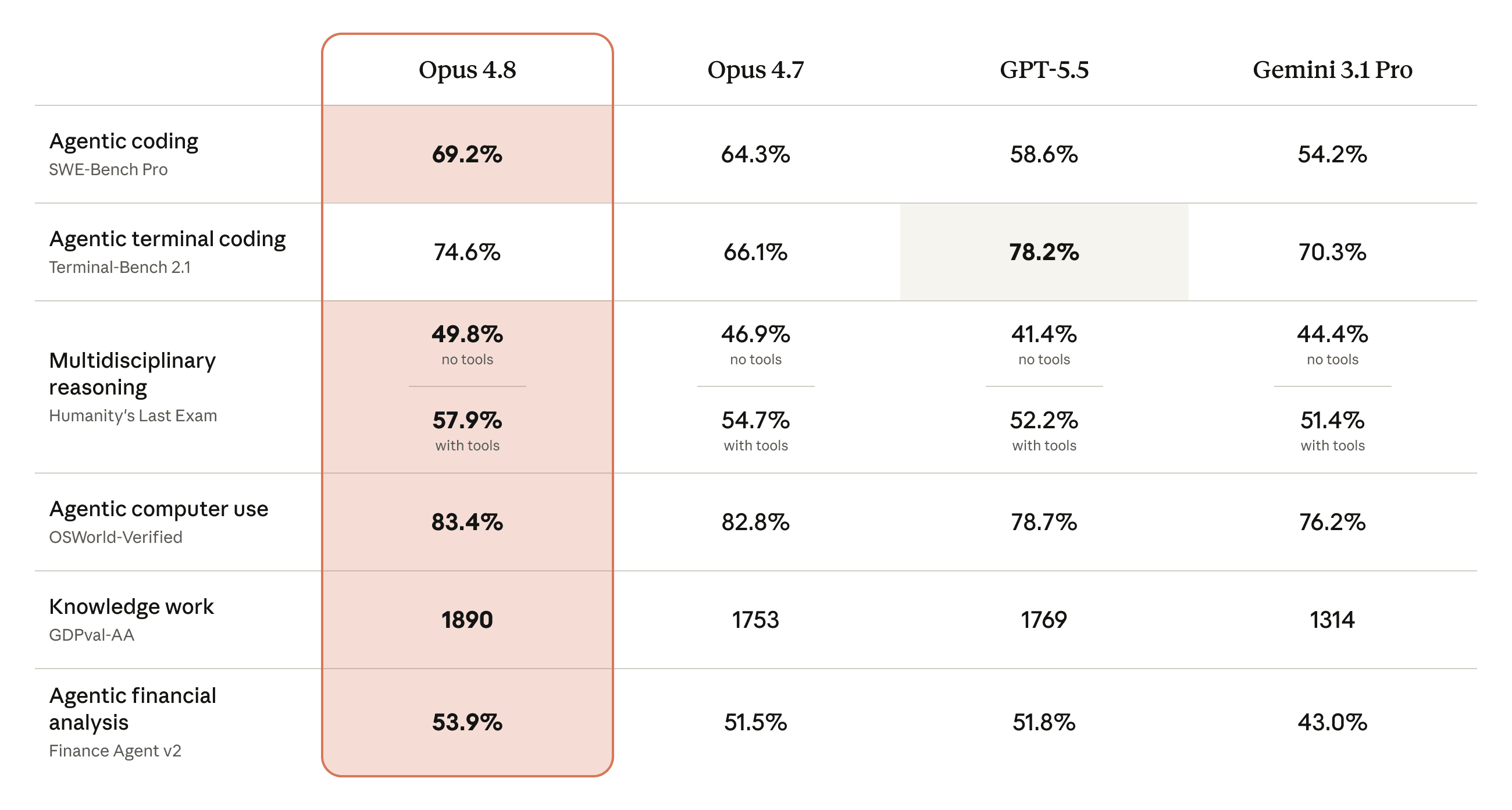
Opus 4.8 posted gains across agentic browser work, legal reasoning, computer-use, multi-step agent tasks, and tool-call efficiency. The headline numbers from Anthropic's announcement and partner statements:
| Benchmark | Opus 4.8 | Opus 4.7 | Notable |
|---|---|---|---|
| Online-Mind2Web | 84% | lower | Strongest computer-use and browser-agent model Hebbia has tested |
| Super-Agent (Hebbia) | Only model to complete every case | partial | Beats prior Opus models and matches GPT-5.5 at parity on cost |
| CursorBench | Exceeds prior Opus across efforts | 70% | Tool calling uses fewer steps for the same intelligence |
| Legal Agent Benchmark (Sierra) | Highest recorded | -- | First model to break 10% on the all-pass standard |
| Terminal-Bench 2.1 | Lead score | baseline | GPT-5.5 with Codex CLI harness scores 83.4% |
| Finance Agent v2 | Lead score | -- | Gemini 3.5 Flash scores 57.9% on the same eval |
| OSWorld-Verified | New evaluation lift | 82.3% | Updated evaluation methodology |
| Databricks Genie (multimodal) | 61% cheaper token cost | baseline | Reasons directly over PDFs, diagrams, unstructured docs |
| Internal honesty eval | ~4x fewer code flaws unremarked | baseline | Anthropic's reported "around four times less likely" multiplier |
The Hebbia and Sierra results are the two that most directly track the autonomous-agent thesis. Kay Zhu at Hebbia called Opus 4.8 "the only model to complete every case end-to-end" on the Super-Agent benchmark, while Niko Grupen at Sierra said Opus 4.8 "delivers the highest score recorded on our Legal Agent Benchmark, and is the first model to break 10% overall on the all-pass standard. For substantive legal work, that's the kind of accuracy lift that translates directly into how much real attorney work our customers can hand off with confidence."
CoCounsel's CTO Joel Hron reported "meaningful improvements in consistency and reasoning quality compared to prior Opus models. For the high-stakes professional workflows our customers depend on, that reliability matters." Investment-side, Michael Ran (Sr. Investment Associate) described "consistently higher quality" output with "noticeably better signal to noise ratio" and singled out "Opus 4.8's tendency to proactively flag issues with the inputs and outputs of an analysis, something other models routinely missed and left to the users to catch."
Dynamic Workflows: The Headline Capability
The single largest behavioral shift Opus 4.8 unlocks ships in Claude Code as Dynamic Workflows. Anthropic describes the mechanism in one line: "Claude can plan the work and then run hundreds of parallel subagents in a single session (and with Opus 4.8, the agents can run for even longer). It then verifies its outputs before reporting back to the user."
The number to anchor on is "hundreds of parallel subagents in a single session." Earlier multi-agent patterns in Claude Code, including Agent Teams, capped at a handful of named specialists. Dynamic Workflows replaces the pre-declared roster with on-the-fly subagent fan-out planned by the parent model. Verification before reporting means the parent agent doesn't just compose the subagent outputs, it audits them before returning to the user.
Dynamic Workflows ships in research preview, gated to Claude Code on Enterprise, Team, and Max plans. For the deeper technical breakdown including command syntax, configuration, and how Dynamic Workflows compares to scheduled tasks and Auto Mode, see Dynamic Workflows in Claude Code.
Two more concrete data points partner CTOs surfaced about the underlying model behavior:
- Tool-calling efficiency. Cursor's Michael Truell: "Tool calling is meaningfully more efficient, using fewer steps for the same intelligence."
- Citation precision under retrieval. Hebbia's Aabhas Sharma: "Claude Opus 4.8 delivers the same strong quality as Opus 4.7 with noticeably better citation precision and more token efficiency on retrieval, which works incredibly well for the kinds of dense filings our customers run every day."
Both qualities matter more inside a Dynamic Workflow than they do in a one-shot chat session. The model is making more calls per task, and bad citations or wasted tool calls compound across hundreds of subagents.
Safety Profile
Opus 4.8's alignment posture takes a step forward from Opus 4.7. Anthropic's assessment, as cited in the announcement, states the model "reaches new highs on our measures of prosocial traits like supporting user autonomy and acting in the user's best interest." Rates of misaligned behavior (deception, cooperation with misuse) are "substantially lower than Opus 4.7, and similar to our best-aligned model, Claude Mythos Preview." This is the first time Anthropic publicly equates a generally available Opus model's alignment to Mythos on these specific measures.
Cybersecurity safeguards remain a gating factor for releasing more capable models. Anthropic states: "Models of this capability level require stronger cyber safeguards before they can be generally released. We're making swift progress on developing these safeguards and expect to be able to bring Mythos-class models to all our customers in the coming weeks." The implication is that Opus 4.8's cyber capability surface sits where Anthropic's safeguard infrastructure can support it, while Mythos-class capabilities stay restricted.
The full evaluation set, including detailed alignment metrics, prompt-injection resistance, and CBRN/cyber evaluations, is documented in the Claude Opus 4.8 System Card. Read the system card directly before deploying Opus 4.8 in regulated or high-risk environments.
New API and Product Features
Alongside the model, Anthropic shipped several new product surfaces:
Dynamic Workflows (research preview). Claude Code on all paid plans, including Pro. Pro enables it from the Dynamic workflows row in /config, Max and Team default on, and Enterprise admins opt in. Lets Claude plan work, dispatch hundreds of parallel subagents, and verify outputs before reporting. See the Dynamic Workflows guide for the full feature breakdown.
New ultracode effort setting. A new option in Claude Code's effort menu that sends xhigh to the model and lets Claude decide on its own when a request warrants a Dynamic Workflow, without the explicit "create a workflow" phrasing. It applies to the current session only. See our ultracode guide for what it does, how it differs from xhigh, max, and ultrathink, and its token-cost profile.
Effort Control in claude.ai and Cowork. A new selector alongside the model picker exposes the effort dial to end users. Anthropic's framing: "On higher effort settings, Claude will think more frequently and more deeply to give better responses. On lower effort settings, Claude will respond faster and use up a user's rate limits more slowly." Available on all plans.
Higher Claude Code rate limits. Anthropic raised the Claude Code rate limits to absorb the heavier token consumption that ships with higher effort levels, ultracode, and Dynamic Workflows fanning out across hundreds of subagents. If your team has been pushing against the previous ceiling, the new headroom matters; see higher usage limits for the broader context on Claude Code rate-limit tiers.
System entries in the Messages API. The messages array now accepts system-role entries inline. Anthropic's description: "Developers can update Claude's instructions mid-task without breaking the prompt cache or routing the update through a user turn. This can be used in a given harness to update permissions, token budgets, or environment context as an agent runs." For long-running agentic harnesses, this removes a frequent source of cache invalidations.
Fast mode pricing reset. Opus 4.8's Fast mode runs "at 2.5x the speed" of standard and is "now three times cheaper than it was for previous models" at $10/$50 per million tokens (input/output). This brings high-throughput agentic workloads into reach at half the previous Fast-mode cost.
Pricing: $5/$25 Standard, $10/$50 Fast Mode
| Tier | Cost |
|---|---|
| Standard tier (all contexts) | $5 input / $25 output per 1M tokens |
| Fast mode (2.5x speed) | $10 input / $50 output per 1M tokens |
| Prompt caching | Up to 90% savings (carried forward) |
| Batch processing | 50% savings (carried forward) |
The standard tier holds at the $5/$25 floor that Opus has settled at since the 4.5 generation. What changed is Fast mode economics: Anthropic states Fast mode is now "three times cheaper than it was for previous models" while delivering "2.5x the speed" of the standard tier. For agentic workloads where throughput matters, this is a real lift, since Dynamic Workflows running hundreds of parallel subagents benefit disproportionately from the speed bump.
Opus 4.8 bills per token, which is the simplest model to reason about: you pay for exactly what you send and receive. That contrasts with the model now sitting above it, Fable 5, which meters through a usage-credit system rather than flat per-token rates. If you are weighing the two, the Fable 5 usage and credits breakdown explains how that credit math works and when the newer model is worth the premium.
Is Claude Opus 4.8 Free?
Claude Opus 4.8 is not free on the claude.ai free tier. It is included at no extra usage cost on the paid plans: Pro, Max, Team, and Enterprise on claude.ai and Cowork. There is no separate per-token charge inside those subscriptions, so "free" in the everyday sense means "included in a plan you already pay for," not "available at $0." Effort Control ships on all of those plans. Dynamic Workflows in Claude Code is gated to Enterprise, Team, and Max plans only during the research preview.
If you want Opus 4.8 without a subscription, you pay per token through the API at the rates below. There is no free API tier for Opus-class models. For a side-by-side of what each Claude plan includes, see model selection.
Claude Opus 4.8 API Pricing
The Claude Opus 4.8 API pricing is $5 per million input tokens and $25 per million output tokens on the standard tier, and $10 per million input and $50 per million output in Fast mode. That works out to half a cent per thousand input tokens, and a quarter of a cent per thousand cached-read tokens once prompt caching kicks in.
| Tier | Input (per 1M) | Output (per 1M) |
|---|---|---|
| Standard | $5 | $25 |
| Fast mode | $10 | $50 |
Pricing applies on Anthropic's direct API, and the model is available on claude.ai and Cowork at launch. Bedrock, Vertex AI, and Foundry availability follows Anthropic's standard rollout pattern but was not enumerated in the launch announcement. Prompt caching continues to cut cached-read cost by up to 90%, and the Batch API holds at 50% discount for non-urgent jobs. For a deeper look at the throughput math behind the Fast-mode tier, see our Fast mode guide.
How to Use Opus 4.8 in Claude Code
Switch your default model:
For per-session overrides:
Effort control via slash command (Claude Code defaults to xhigh on Opus 4.8):
To use Dynamic Workflows (Enterprise, Team, or Max plan required):
The model API identifier is claude-opus-4-8. It is available across claude.ai, the Messages API, Cowork, and Claude Code on launch day. For the practical patterns most developers will want to keep using, see best practices for agentic coding. Most of the Opus 4.7 playbook (xhigh defaults, explicit instructions, adaptive thinking) carries forward.
Opus 4.8 vs Opus 4.7: What Changed
| Feature | Opus 4.7 | Opus 4.8 |
|---|---|---|
| Online-Mind2Web | <84% | 84% (strongest computer-use model Hebbia tested) |
| Super-Agent (Hebbia) | partial completion | Only model to complete every case end-to-end |
| CursorBench | 70% (high effort) | Exceeds prior Opus across every effort level |
| Legal Agent Benchmark | -- | Highest recorded; first to break 10% on all-pass |
| Multimodal token cost | baseline | 61% cheaper on Databricks Genie eval |
| Honesty (code flaw passthrough) | baseline | ~4x less likely to allow flaws to pass unremarked |
| Alignment vs Mythos | "well-aligned and trustworthy, not fully ideal" | Misaligned behavior rates similar to Mythos Preview |
| Tool calling | Standard | "Meaningfully more efficient, using fewer steps" |
| Autonomous session length | Hours-long, coherent | "Agents can run for even longer" with Dynamic Workflows |
| Fast mode pricing | Previous Fast mode rate | $10/$50 per 1M, 3x cheaper than previous Fast modes |
| Fast mode speed | baseline | 2.5x standard tier |
| Default user-facing effort | API-only effort dial | Effort Control selector in claude.ai and Cowork |
| Effort levels in Claude Code | low–max, default xhigh | low–max, default high, plus new ultracode setting |
| Claude Code rate limits | Previous ceiling | Raised to absorb ultracode + Dynamic Workflows |
| Messages API system entries | Not supported | System entries inline in messages array |
| Multi-agent fan-out | Named Agent Teams | Dynamic Workflows: hundreds of parallel subagents |
| Standard pricing | $5/$25 per 1M | $5/$25 per 1M (unchanged) |
The core story is reliability, not raw capability. Opus 4.7 was a vision and verification release. Opus 4.8 is a tool-calling, autonomous-session, and alignment release. Partners are not reporting a new ceiling on what the model can do; they are reporting that it does the same kinds of work with fewer mistakes, fewer steps, and less hand-holding. Cognition's Scott Wu was direct: Opus 4.8 "improves on Opus 4.6 and fixes the comment-verbosity and tool-calling issues we saw with Opus 4.7."
For model selection, the upgrade path is straightforward. If you use Opus 4.7 today, switch to 4.8. Existing Opus 4.7 prompts and Claude Code configurations carry forward without API changes. If you run high-throughput agentic workloads, evaluate Fast mode at the new $10/$50 rate. If you operate Claude Code on an Enterprise, Team, or Max plan, request Dynamic Workflows research-preview access.
Frequently Asked Questions
Is Claude Opus 4.8 free? Opus 4.8 is included on Claude Pro, Max, Team, and Enterprise plans. It is not on the claude.ai free tier. API access is paid at $5/$25 per million tokens on the standard tier or $10/$50 on Fast mode.
What is the Opus 4.8 context window? 1 million tokens, generally available at standard pricing. Max output is 128,000 tokens per response.
How many parameters does Claude Opus 4.8 have? Anthropic does not disclose parameter counts for any Claude model, including Opus 4.8. The published specs are the 1M-token context window, 128,000-token max output, and the $5/$25 pricing. Treat any specific parameter figure you see elsewhere as speculation.
Is Opus 4.8 better than GPT-5.5? On agentic browser work (Online-Mind2Web) Opus 4.8 leads at 84%, and on Hebbia's Super-Agent benchmark it completes every case end-to-end while matching GPT-5.5 at parity on cost. GPT-5.5 with the Codex CLI harness still leads Terminal-Bench 2.1 at 83.4%. The honest answer is workload-dependent: Opus 4.8 is stronger for sustained, tool-heavy agentic sessions.
Does Opus 4.8 break existing Opus 4.7 API code? No breaking API changes were announced. The Messages API gains a new optional capability (system entries inline) but existing payloads continue to work. Effort control parameters carry forward.
What are the new effort levels in Opus 4.8? The Claude Code effort dial now exposes four settings: high (default in the Messages API), xhigh (Claude Code default), ultracode (new in 4.8, runs at xhigh and auto-triggers Dynamic Workflows when the request scope warrants it), and max. The user-facing Effort Control selector in claude.ai and Cowork maps to the same dial. xhigh was introduced in Opus 4.7 and carries forward; ultracode is the new tier.
How does Opus 4.8 compare to Mythos? Mythos Preview remains Anthropic's most capable model and stays restricted to Project Glasswing partners. Opus 4.8's alignment metrics ("rates of misaligned behavior substantially lower than Opus 4.7, and similar to Claude Mythos Preview") are the closest a generally available model has gotten to Mythos. Anthropic states Mythos-class models will become broadly available "in the coming weeks."
What is Dynamic Workflows and how do I use it? Dynamic Workflows is a new Claude Code capability shipping in research preview on Enterprise, Team, and Max plans. Claude plans the work, runs hundreds of parallel subagents in a single session, and verifies outputs before reporting back. Full details are in the Dynamic Workflows guide.
Related Pages
- Claude Sonnet 5 for the cheaper daily-driver you escalate to Opus 4.8 from
- Sonnet 5 vs Opus 4.8 for the cost-versus-capability decision
- GLM 5.2 vs Opus 4.8 vs Sonnet 5 for how Opus 4.8 compares to the leading open-weights model
- Every Claude Model for the full lineup and timeline
- Model selection guide for choosing the right model per task
Last updated on